
Was erwartet dich hier?
Intro
Aktuell bin ich bei einem Kunden an einem Code Review beteiligt. Dabei beleuchten wir neben der Applikation auch alle Schnittstellen.. Dazu gehört natürlich auch die Sql Server Landschaft, welche ich Anfang des Jahres aufgesetzt habe.
Das Ergebnis waren doch mehr Findings in meine Richtung als erwartet und ich fühlte mich sofort gechallenged. Das Meiste konnte ich widerlegen, bei einigen Themen war der Kunde in der Pflicht und ein Thema hat mich rein interessenhalber gepackt.
Read- und Write Latenzen der TempDB ( und jeder anderen DB )

Vorgeschichte
Der Kunde betreibt kein eigenes Rechenzentrum, ist somit vom Hoster abhängig, welcher leider nicht sehr kommunikativ ist. Somit musste ich mir auf diverse andere Wege ein Bild von der total overcommitteten Hardware machen und den Hoster Challengen. Dies war auch der Grund, warum ich ziemlich genau im Bilde war, was die Hosts und Storage Systeme des Hosters im Stande waren zu leisten.
Deshalb hat es mich doch sehr gewundert, dass als Finding 32ms Write Latency aufgeführt waren. Keine Frage, das ist ein schlechter Wert für AllFlash NVMe aber der stand da einfach so im Report, ohne Differenzierung oder tiefere Analysen. Nur die Aussage schlechter Storage. Also habe ich meine Werkzeuge ausgepackt, mir das noch mal angeschaut und auch eine neue Lösung entwickelt, die ich mit euch teilen möchte.
DISKSPD
Repo: perf_diskspeed/DISKSPD
Microsoft: https://github.com/microsoft/diskspd
Mit DISKSPD sollte man auf unbekannten Systemen immer anfangen, oft liegt hier schon ein großer Anteil an Problemen versteckt. Bei diesem Kudnen lief zum Beispiel eine DB mit hohem Workload auf Spindeln, mit Latenzen in der .2 Perzentile mit 15 Sekunden Latenz, dazu 14MB Durchsatz. Da brauche ich mir um Indexe usw. keine Gedanken mehr machen.
Um schnell an Ergebnisse zu kommen, habe ich mir einen Wrapper für DISKSP gebaut, welcher immer 3 Standardtests ausführt
- Sql Server Workload
- Random 64KB Workload
- Sequenziell 64KB Workload
Die Dateien werden separat im Unterordner _Output gespeichert und ermöglichen somit recht gute Hinweise auf Storage-Probleme. Nun waren das wie erwartet super Werte, welche NVMe Storage entsprechen. Also weiter zu Sql Server und wir schauen mal was uns dieser so sagt.
sys.dm_io_virtual_file_stats
Sql Server bietet eine View, in der alle Metriken der Files sauber aufgelistet werden.
select * from sys.dm_io_virtual_file_stats(null,null)
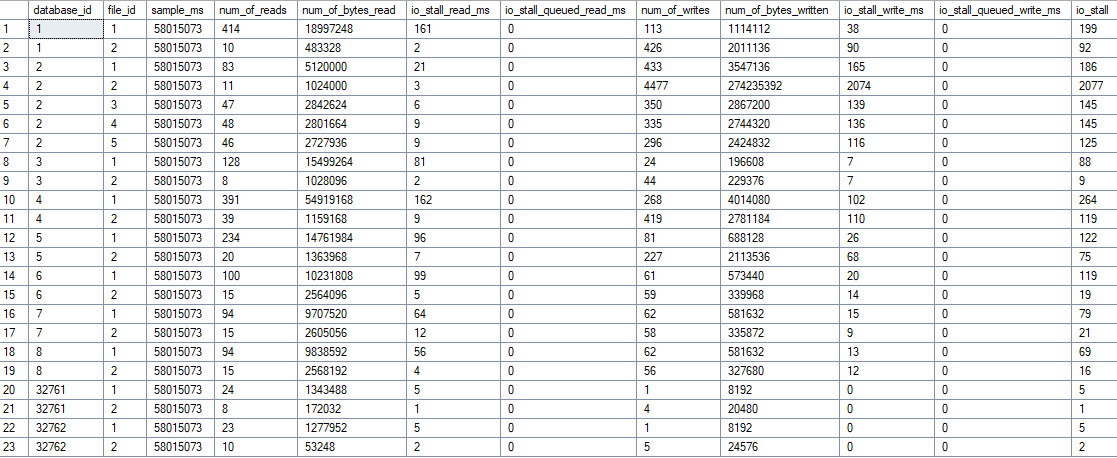
Darauf basierend habe ich ein Analyse Script gebaut, welches mir mehr Infos gibt und ich auch weitere Rückschlüsse wie ReadWrite Ratio, wahrscheinliche IOPS auf Basis der Anzahl der Vorgänge und auch Mengen. Damit kann man schon ganz gut Storage Systeme zu speziellen Workloads aufbauen.
Und auch dieser Wert hat mir 32ms Write Latency der TempDB angezeigt. Dann habe ich angefangen mich zu fragen, wie entstehet dieser Wert überhaupt?

Grundlegende Berechnung der Werte
SQL Server misst I/O-Latenz durch einfache Division der kumulativen Wartezeiten durch die Anzahl der Operationen:
-- Read Latency in ms
io_stall_read_ms / num_of_reads = durchschnittliche Read-Latenz
-- Write Latency in ms
io_stall_write_ms / num_of_writes = durchschnittliche Write-Latenz
Thats it!!! Und nun sollte klar sein, dass die punktuelle Nutzung dieser DMV nicht wirklich aussagekräftig ist, im Gegenteil. Die Werte können wie bei dem Review Unternehmen, was sich auf solche Prozesse spezialisiert hat, zu falschen Rückschlüssen und Handlungsempfehlungen führen. Gruselig.
Wenn das Storagesystem seit dem Start von Sql Server mal hart Schluckauf hatte, sind die Metriken verunreiningt. Laut meinen Recherchen kann man diese nicht flushen, nur durch das Offline nehmen der DB, was ich üblicherweise in produktiven Umgebungen vermeide.
Nach ein paar weiteren Runden in meinem Kopf kam recht schnell die Lösung. Das sind alles SnapShot Values, ich brauche ja nur das Delta zwischen zwei Werten und schon habe ich reale Werte. Und das Ganze kann ich auch noch in eine Zeitreihe packen und habe eine Langzeitanalyse. Mindblowing 😝
Google hat auch schnell entsprechende Lösungen aufgezeigt, die ich als Basis Idee genutzt habe. Danke an Paul Randal ( sqlskills.com )
Für die Analyse einer kompletten Woche ist dies aber auch nicht geeignet. Somit habe ich das Ganze auf eine Langzeitanalyse mit persistenten Table erweitert.
Die Lösung –> snapDiskLatency
Repo: perf_diskspeed/snapDiskLatency
Was macht snapDiskLatency?
Das Problem ist bekannt – die Standard-DMV sys.dm_io_virtual_file_stats zeigt kumulative Werte seit dem SQL Server Start. Ein einziger Storage-Schluckauf vor Wochen und die Latenzwerte sind nicht mehr repräsentativ.
snapDiskLatency löst das Problem mit zwei simplen Stored Procedures:
Die Erste sammelt stündlich die Rohdaten aus der DMV und schreibt sie in einen permanenten Table. Warum stündlich? Kürzere Intervalle führen zu unzuverlässigen Delta-Berechnungen – zu wenig I/O zwischen den Snapshots macht die Werte ungenau. Dies kann aber individuell angepasst werden, da der Agent die Prozedur triggert.
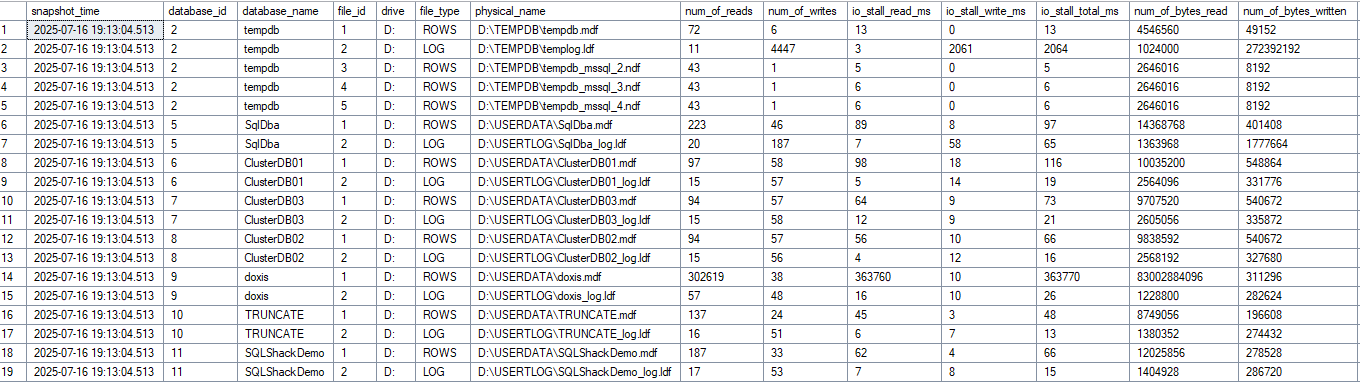
Die Zweite macht die Delta-Berechnungen zwischen den Snapshots und erstellt das Resultset. Somit werden reale Latenzwerte für definierte Zeiträume erzeugt, ohne historischen Schluckauf, welche dann mit anderen Metriken abgeglichen werden können.
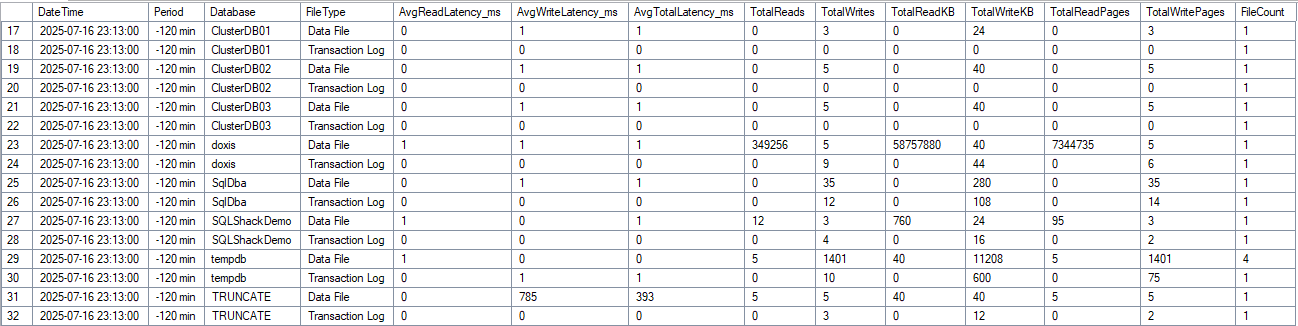
Hier sehen wir zum Beispiel im TRUNCATE Table einen Aureißer ( hier liegt auch NVMe drunter ). Auf dem LAB System ist keine Last, DOXIS ist nur ein Table mit 2 Spalten und wurde künstlich mit Workload bearbeitet.
Das Ergebnis
Statt möglicherweise verunreinigten Werten
- Durchschnittliche Latenzen pro Intervall
- Read/Write-Verhältnisse
- Aufschlüsselung nach Datenbank und File-Type
Setup
Agent Job erstellen, stündlich laufen lassen, fertig. Die komplette Anleitung steht in der README, copy & paste & freuen

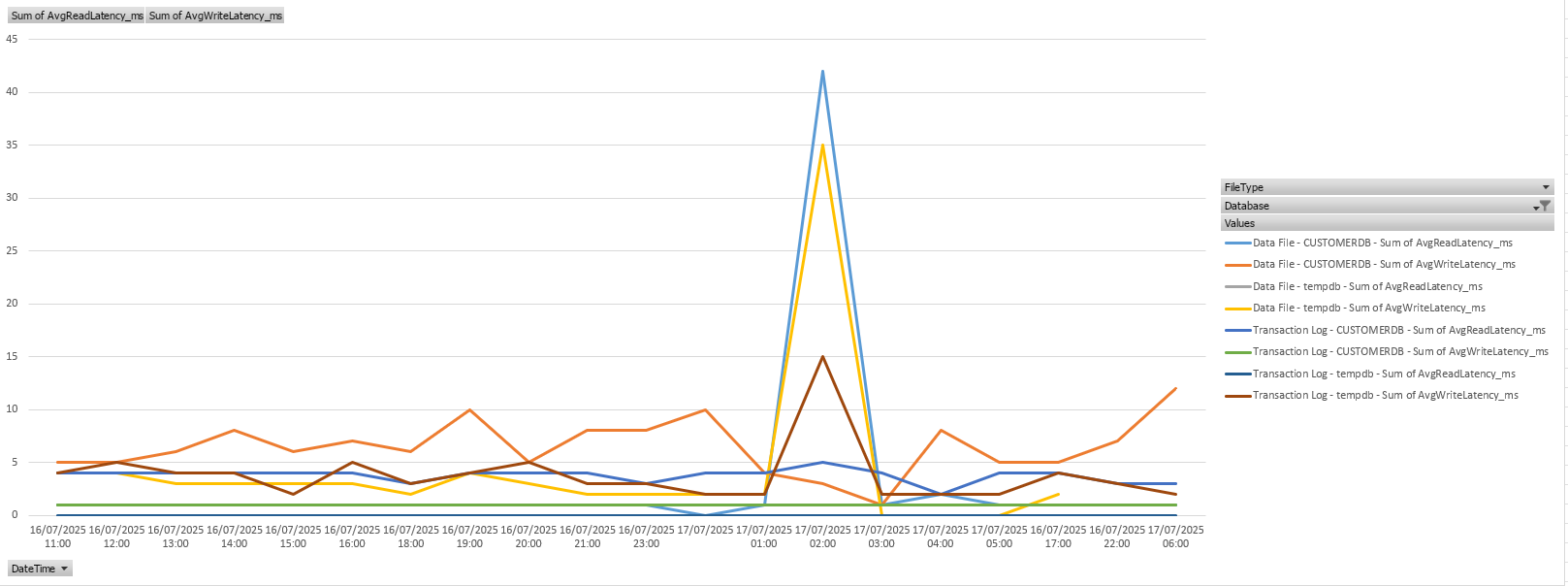
Diagramme
Da dies auch jedes gute propritäre DatabaseMonitoringTool macht und hübsch grafisch darstellt, will ich zumindest eine Möglichkeit in Excel im Ergebnis zeigen. Dazu muss das Ergebnis der DataSource oder Copy pivotiert werden und schon kann man gut seine Daily Peaks erkennen.
Schreibe einen Kommentar